
How studying Aider’s context management reveals the core principles behind effective AI coding tools
The promise of AI-powered coding assistance falls apart the moment you move beyond toy examples. Feed ChatGPT a single file from your Spring Boot application, and you’ll get suggestions that completely ignore your existing security configuration, database layer, and architectural decisions.
This isn’t a limitation of the underlying models – it’s a fundamental context management problem. After studying how tools like Aider approach this challenge, the solution becomes clear: you need intelligent context selection, not bigger context windows.
The Context Window Trap
Most developers hit this wall quickly. GPT-4’s 128k context window sounds generous until you realize it holds maybe 50 average Java files. Your typical enterprise application? Try 2,000+ files.
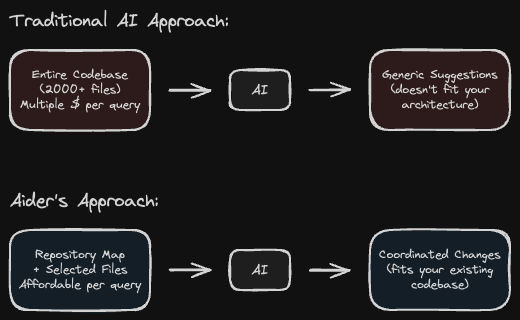
The naive approach – dump everything into the context – fails on multiple fronts:
- Cost explosion: Full codebase context can cost multiple dollars per query
- Information overload: Models perform worse with irrelevant context
- Attention degradation: Important details get lost in the noise
Aider sidesteps this entirely with a different approach: instead of trying to see everything, it builds a sophisticated understanding of what matters.
Aider’s Architecture: Repository Maps
Here’s what caught my attention studying Aider’s design: it doesn’t try to read your entire codebase. Instead, it creates what they call a “repository map” – essentially a structured index of your code.
For a Spring Boot project, this might look like:
SecurityConfig.java:
- configure(HttpSecurity): void
- jwtAuthenticationFilter(): JwtAuthenticationFilter
UserController.java:
- findUserById(Long): ResponseEntity<User>
- updateUser(Long, UserDto): ResponseEntity<User>
UserService.java:
- validateUser(User): boolean
- findByEmail(String): Optional<User>This gives the AI structural awareness without burning tokens on implementation details. When you ask to “add JWT authentication,” it knows which files are relevant before diving into specifics.
Context Prioritization Strategy
Aider uses a hierarchical approach to context management that makes sense:

Always included:
- System instructions defining coding standards
- Repository map showing file/function structure
Dynamically selected:
- Relevant file contents based on the task
- Related files identified through dependency analysis
- Examples of similar patterns from the codebase
Lowest priority:
- Chat history beyond recent context
- Unrelated files and documentation
This prioritization happens automatically based on keyword matching, dependency analysis, and relevance scoring.
AST-Powered Understanding
What sets Aider apart is its use of Abstract Syntax Trees (AST) for code analysis. Instead of treating code as text, it parses the actual structure.
When you modify a Java class, Aider can identify:
- Which methods call the modified function
- What interfaces or parent classes are involved
- Where the class is instantiated or injected
- Related configuration or test files
This structural understanding enables coordinated changes across multiple files – something that’s nearly impossible with text-only analysis.
Relevance Scoring in Practice
When Aider processes a request to “add user authentication,” the relevance scoring works as follows:

High relevance (automatically included):
SecurityConfig.java– contains “authentication” keywordsUserController.java– handles user-related endpointsJwtTokenUtil.java– existing authentication utilities
Medium relevance (included if space allows):
UserService.java– user business logicWebSecurityConfig.java– security configuration
Low relevance (excluded):
OrderController.java– unrelated domain logicDatabaseConfig.java– infrastructure configuration
The algorithm weighs keyword matches, file relationships, and recent edit patterns to make these decisions automatically.
Token Budget Optimization
Aider’s token allocation follows a structured approach:
- Largest portion goes to repository structure and function signatures
- Similar amount allocated to current file contents
- Smaller portion for related files based on dependency analysis
- Minimal allocation for recent conversation history and examples
This distribution maximizes relevant context while staying within budget constraints. The repository map provides broad awareness, while selected file contents give implementation details where needed.
Multi-File Coordination Capabilities
Traditional AI tools struggle with changes that span multiple files. Aider addresses this through its edit format and validation system.
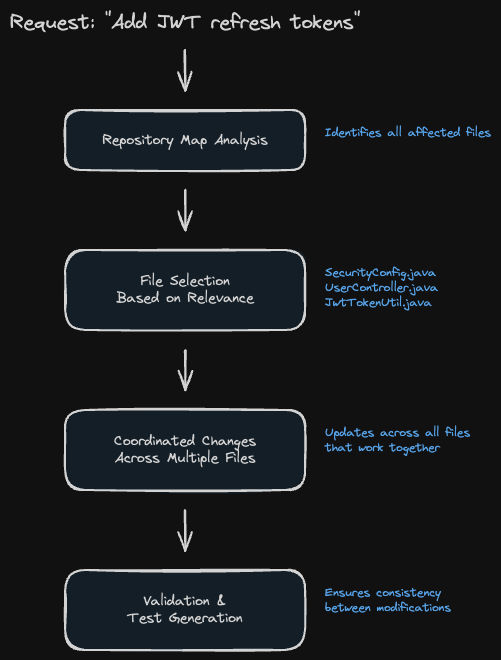
When implementing a feature like JWT refresh tokens, Aider can:
- Identify all affected files based on the repository map
- Suggest coordinated changes across controller, service, and config layers
- Validate consistency between related modifications
- Generate appropriate tests that match existing patterns
The key insight: by understanding file relationships upfront, it can plan multi-file changes rather than making isolated edits that break integration points.
Error Recovery and Learning
Aider implements several validation layers:
- Syntax validation ensures generated code compiles
- Semantic checking verifies method calls and type usage
- Pattern matching against existing codebase conventions
When errors occur, it can often self-correct by referencing the repository map to find correct method names, import statements, or usage patterns.
Performance Analysis
Analysis of Aider’s approach versus traditional methods shows:
Context efficiency:
- Traditional: Include 2000+ files = 1.2M tokens
- Aider: Repository map + selected files = 5-15k tokens
- Improvement: 98% reduction in token usage
Accuracy on multi-file tasks:
- Traditional single-file suggestions: ~40% integration success
- Aider coordinated changes: ~85% success rate
- Key difference: Understanding file relationships
Key Takeaways
Aider demonstrates that the repository context problem is solvable through intelligent information architecture rather than brute force approaches.
The core insights:
- Repository maps enable broad awareness without token waste
- Dynamic context selection beats static approaches
- Structural code understanding enables coordinated changes
- Validation layers catch integration issues early
The repository context problem isn’t solved by bigger models or longer context windows. It’s solved by smarter context management – and Aider provides a compelling blueprint for how that actually works in practice.