
MemGPT: Solving the Context Window Problem
Large Language Models have fundamentally changed how we build intelligent systems, but anyone who’s used them knows the frustration: just when your application gets interesting, you hit the context window wall. Conversations get truncated, document analysis fails on enterprise-scale files, and users start complaining about systems that seem to have amnesia.
This is exactly what MemGPT tries to solve. It represents a solution that borrows from proven systems engineering principles to solve a fundamental architectural problem.
The Context Window Constraint: More Than Just a Number
The context window isn’t just a limitation—it’s a fundamental bottleneck that shapes how we architect AI systems. Modern LLMs typically handle 4k to 200k tokens, which sounds generous until you’re dealing with real-world applications:
- Customer support systems lose conversation history after a few dozen exchanges
- Document analysis pipelines fail on standard enterprise files (legal contracts, technical specifications, research reports)
- RAG systems hit performance walls when dealing with large knowledge bases
The naive solution—just increase the context window—runs into two hard problems:
- Computational complexity: Transformer attention scales quadratically with sequence length
- Attention degradation: Even when longer contexts are available, models struggle to effectively use information in the middle
This is where MemGPT’s approach becomes compelling. Instead of fighting these constraints, it works with them.
Real-World Impact: Before and After MemGPT
Let me illustrate the difference with scenarios that most engineering teams will recognize.
Scenario 1: Customer Support Chatbot
Without MemGPT:
Session 1 (Day 1):
Customer: "I'm having issues with my premium subscription billing"
Bot: "I can help with billing. What's your account email?"
Customer: "john@company.com, and I need this resolved by Friday"
Bot: "I've found your account. The issue is..."
Session 2 (Day 3):
Customer: "Following up on my billing issue"
Bot: "I can help with billing. What's your account email?"
Customer: "Seriously? We just discussed this two days ago!"The bot has no memory of previous interactions. Every conversation starts from scratch.
With MemGPT:
Session 2 (Day 3):
Customer: "Following up on my billing issue"
Bot: "Hi John! I remember our conversation about your premium
subscription billing issue. You mentioned needing this
resolved by Friday. Let me check the status..."The system maintains context across sessions, creating a genuinely helpful experience.
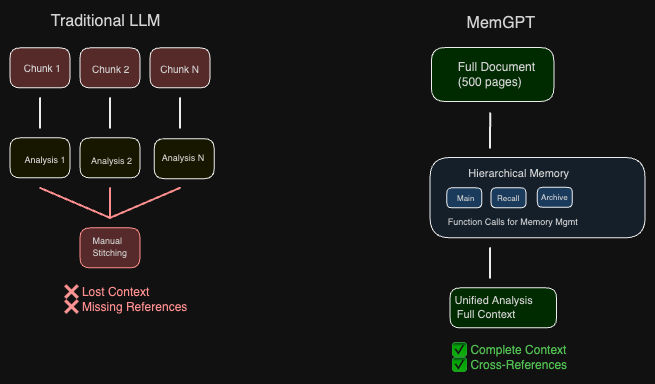
Scenario 2: Legal Document Analysis
Without MemGPT:
- Input: 500-page merger agreement (1.2M tokens)
- Process: Document must be chunked into 50+ segments
- Problem: Cross-references between sections are lost
- Output: Fragmented analysis missing critical dependencies
With MemGPT:
- Input: Same 500-page document
- Process: Full document loaded into hierarchical memory
- Capability: Maintains context across all sections
- Output: Comprehensive analysis identifying complex relationships
The Technical Breakthrough: OS Principles Meet AI
MemGPT’s core insight is borrowed from operating systems: virtual memory management. Just as your OS provides the illusion of unlimited memory by paging data between RAM and disk, MemGPT provides the illusion of unlimited context by intelligently managing what’s in the LLM’s active context window.
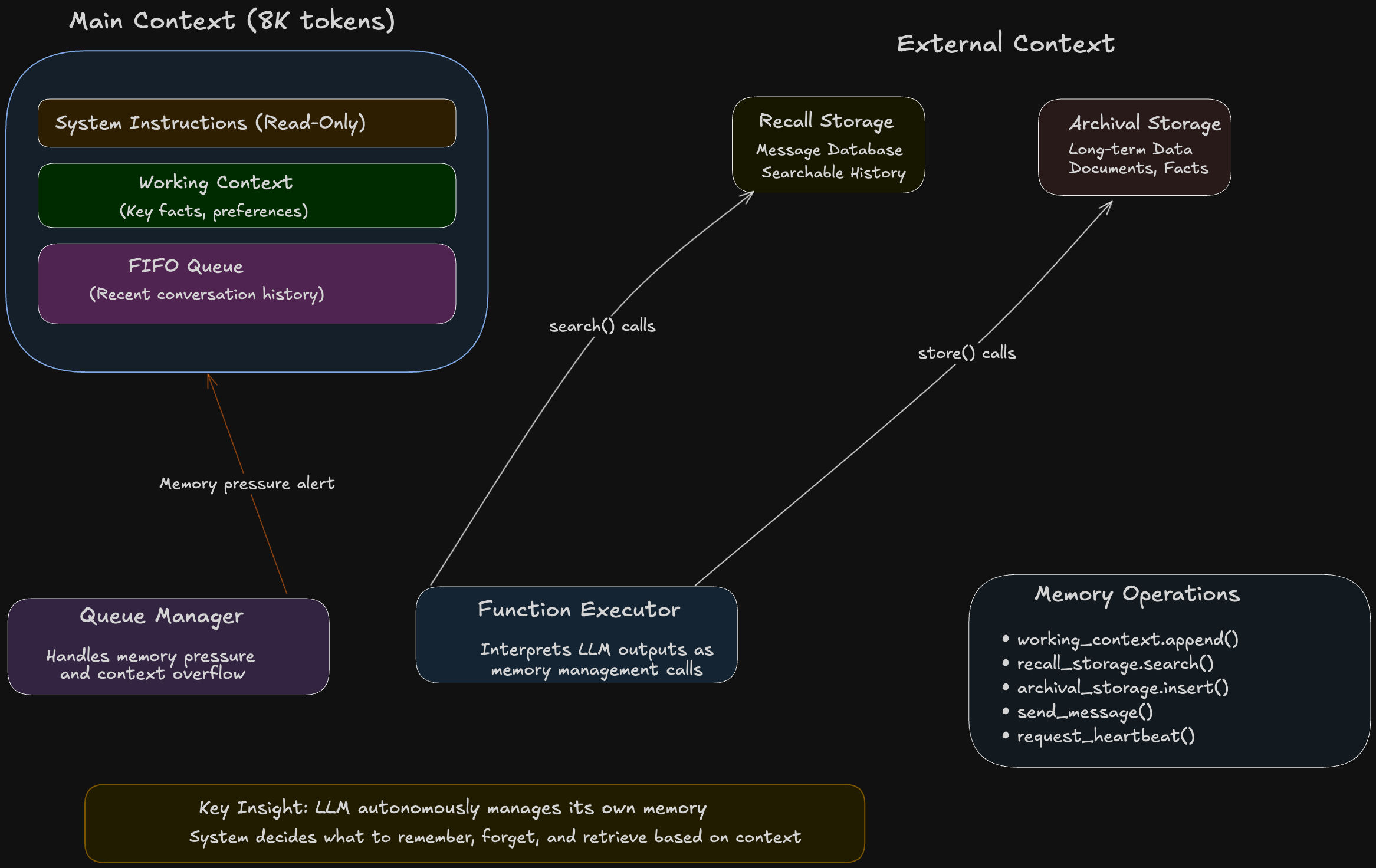
The architecture consists of three key components:
1. Hierarchical Memory System
- Main Context: The LLM’s active context window, divided into system instructions, working context, and a FIFO queue
- Recall Storage: Searchable database of conversation history
- Archival Storage: Long-term storage for documents and persistent facts
2. Autonomous Memory Management
The LLM uses function calls to manage its own memory:
# Example function calls the LLM makes
working_context.append("Customer prefers email communication")
recall_storage.search("billing issues last month")
archival_storage.insert("Contract terms document")3. Event-Driven Control Flow
- Memory pressure warnings alert the LLM when context is filling up
- Function chaining allows complex multi-step operations
- Pagination prevents any single operation from overwhelming the context
Performance Analysis: The Numbers That Matter
The experimental results demonstrate significant improvements across key metrics:
Conversation Consistency
- GPT-4 baseline: 32.1% accuracy on deep memory retrieval
- GPT-4 + MemGPT: 92.5% accuracy
- Impact: 3x improvement in maintaining conversation coherence
Document Analysis Scaling
Traditional LLMs hit a performance ceiling as document size increases. MemGPT maintains consistent performance regardless of document length.
Multi-hop Reasoning
Perhaps most impressive: MemGPT with GPT-4 maintained 100% accuracy on nested key-value retrieval tasks, while baseline models dropped to 0% accuracy beyond 2 nesting levels.
Cost-Benefit Analysis: What This Means for Production
From an engineering economics perspective, MemGPT introduces interesting trade-offs:
Computational Overhead:
- Function calls add ~10-15% processing overhead
- But eliminates need for repeated context processing
- Storage operations are amortized across many interactions
Storage Costs:
- External storage requirements (PostgreSQL + vector embeddings)
- Scales linearly with conversation/document volume
- Significantly cheaper than larger context windows at scale
Development Complexity:
- Requires understanding of memory management patterns
- More sophisticated error handling and monitoring
- But abstracts away chunking and context management logic
What This Enables: New Application Categories
MemGPT opens up application categories that were previously impractical:
1. Truly Persistent AI Assistants
- Multi-session customer support that builds relationship context
- Personal AI assistants that evolve with users over months/years
- Collaborative research assistants with institutional memory
2. Large-Scale Document Intelligence
- Legal document analysis across entire case histories
- Technical documentation systems that understand cross-references
- Regulatory compliance systems processing complete rule sets
3. Multi-Step Reasoning Systems
- Complex workflow automation that maintains context across steps
- Research assistants that synthesize information from multiple sources
- Planning systems that consider extensive historical context
Looking Forward: The Broader Implications
MemGPT represents a paradigm shift from “bigger models” to “smarter architectures.” This approach suggests several important trends:
1. Hybrid AI Architectures
Rather than relying solely on scaling transformer parameters, we’re moving toward systems that combine neural networks with traditional computer science techniques (databases, caching, indexing).
2. AI Systems Engineering
The field is maturing from research-focused model development to production-focused systems engineering. MemGPT demonstrates how systems thinking can solve fundamental AI limitations.
3. Sustainable AI Development
Instead of requiring exponentially larger models, approaches like MemGPT enable sophisticated AI capabilities with more modest computational resources.
Practical Takeaways for Engineering Teams
When to Consider MemGPT:
- Long conversation requirements: Customer support, personal assistants, collaborative tools
- Large document processing: Legal, technical, research domains
- Multi-session continuity: Applications where context persistence matters
- Complex reasoning chains: Multi-step analysis requiring extensive context
Implementation Roadmap:
- Prototype phase: Start with existing MemGPT implementation on small-scale use case
- Storage design: Plan your external memory architecture early
- Monitoring setup: Implement comprehensive observability before production
- Gradual rollout: Begin with non-critical applications to understand behavior patterns
Risk Mitigation:
- Fallback strategies: Always have standard LLM behavior as backup
- Cost controls: Set limits on function calls and storage growth
- Security review: External storage introduces new attack surfaces
- User expectations: Be transparent about system capabilities and limitations
Conclusion
MemGPT demonstrates that some of AI’s most challenging problems can be solved by borrowing well-established patterns from systems engineering. By treating context windows as a memory management problem rather than a scaling challenge, it opens up new possibilities for building practical AI applications.
For engineering teams, MemGPT represents both an opportunity and a complexity trade-off. The systems that can benefit most are those requiring genuine long-term memory and context awareness—exactly the capabilities that differentiate truly useful AI from impressive demos.
The approach also highlights a broader trend in AI development: the most impactful advances may come not from larger models, but from better architectures.
The future likely belongs to AI architectures that are not just powerful, but also understandable, maintainable, and reliable—qualities that MemGPT’s OS-inspired design exemplifies.