
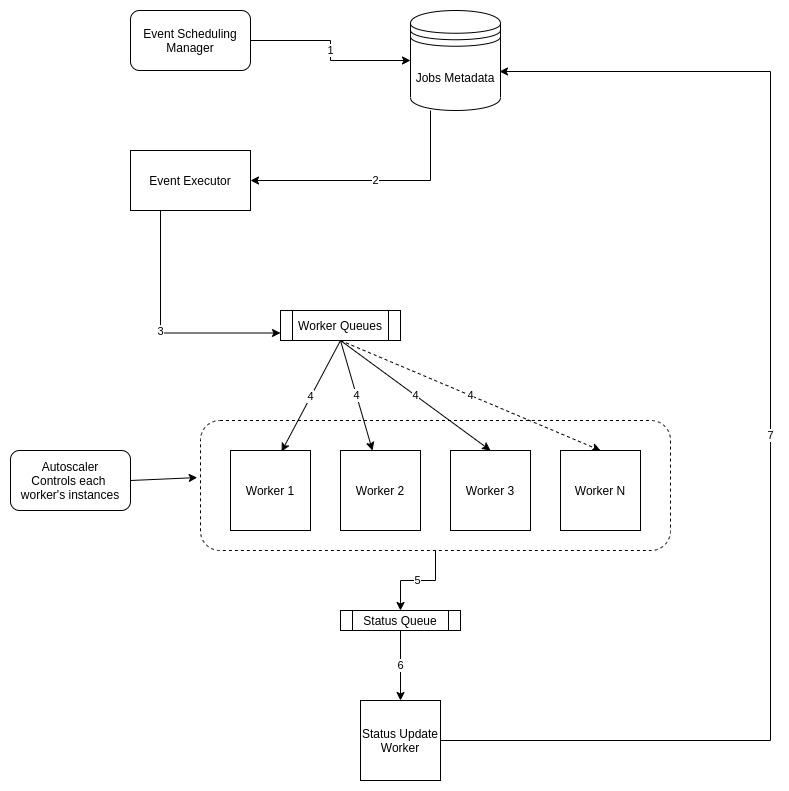
Let’s go through the design depicted by the above image.
Event scheduling manager
This is the interface for creating, deleting or getting status of a job.
Workflow
- Scheduling manager receives a request to create a job. Job metadata is stored in the Jobs DB via a rest call. Although depending on the influx of calls, another component can be added here which can store data asynchronously into the database. The metadata should store the trigger time in addition to other details.
- Job executor continuously polls the jobs DB for collecting the jobs which
- Surpassed their trigger time
- Failed and should be re-tried
- Job executor creates messages with the metadata from jobs db and forwards them to the respective queue.
- Before the messages are sent to the message bus, the job’s status should be updated to be in progress in the jobs db.
- To support requirement for recurring tasks, another instance of the same job can be created in the db by calculating their next trigger time based on the time interval specified in the job’s metadata.
- These messages will be picked up by respective consumers from the queues and processed.
- Once the respective tasks have been completed by the workers, the status of the task is set to the outgoing message response. Irrespective of status value from the worker, messages are routed to a status worker.
- The status worker consumes messages from status queue.
- Status worker updates the status of the job in the db.