
This is Part 2 of a two-part series. Part 1 covered the strategic vision and architectural principles. Part 2 focuses on implementation: protocols, code, failure modes, and production patterns.
Introduction
Part 1 explored why agentic systems require fundamentally different architectural patterns. The Agent Mesh was introduced as a coordination layer for autonomous, goal-seeking systems.
Now, let’s get technical.
This post walks through the actual implementation concerns: how agents communicate, how memory is structured, how policies are enforced, and most critically — how these systems fail and recover.
We will build up from first principles, using a DevOps automation scenario as the reference implementation.
The Reference Scenario: A DevOps Agent Mesh
To understand the architecture, consider a concrete challenge: Automating cloud cost and performance optimization.
The Problem: Uncoordinated Autonomy
Imagine three autonomous agents deployed without a coordination layer:
- Cost Monitor: Wants to minimize spend. It sees an expensive server and kills it.
- Performance Optimizer: Wants to maximize uptime. It sees a dead server and spins up a bigger one.
- Capacity Planner: Wants stable growth. It sees rapid churn and reserves instances for 3 years.
Result: The agents are at war. They create an infinite loop of provisioning and de-provisioning, burning money faster than a human ever could.
The Solution: Coordinated Intent
In an Agent Mesh, these agents do not just act; they negotiate intents.
The Mesh Architecture:
(Note: Visual illustrates the flow: Cost Agent emits ‘Investigate’ Intent → Intent Bus → Performance Agent consumes → Checks Policy → Proposes Action)
The Agents:
- Cost Monitor Agent: Tracks spending patterns, detects anomalies.
- Performance Optimizer Agent: Analyzes application metrics and bottlenecks.
- Capacity Planner Agent: Forecasts resource needs and balances trade-offs.
The Workflow:
- Cost Monitor detects a spending spike → emits an Intent (not a command) to “Investigate”.
- Performance Optimizer picks up the intent → identifies a bottleneck → consults Capacity Planner.
- Capacity Planner proposes scaling → checks Policy for budget impact.
This is contextual orchestration — decisions emerge from agent collaboration rather than fixed pipelines.
1. Agent Communication: The Intent Protocol
The Problem with Traditional APIs
Traditional REST APIs require explicit contracts (e.g., POST /api/campaigns/create), which are too rigid for autonomous agents. Agents need to express goals (‘reduce churn’) and constraints (‘budget < $50k') rather than executing predefined steps, allowing the receiving system to decide the best execution path.
Intent-Based Communication
Instead of “create a campaign with these parameters,” agents express:
{
"intent_type": "reduce_churn",
"context": {
"segment": "high_value_churners",
"urgency": "high",
"current_churn_rate": 0.23
},
"constraints": {
"max_discount": 0.15,
"budget_remaining": 50000,
"must_comply_with": ["gdpr", "can_spam"]
},
"success_criteria": {
"target_churn_rate": 0.15,
"min_roi": 1.5
}
}The receiving agent interprets this and decides how to achieve the goal.
Intent Schema Structure
Every intent in this reference architecture follows this pattern:
from dataclasses import dataclass
from typing import Dict, List, Optional
from enum import Enum
class IntentType(Enum):
INVESTIGATE = "investigate"
OPTIMIZE = "optimize"
SCALE = "scale"
ALERT = "alert"
@dataclass
class Intent:
"""Core intent structure for agent communication"""
intent_id: str # Unique identifier for tracing
from_agent: str # Source agent ID
to_agent: Optional[str] # Target agent (None = broadcast)
intent_type: IntentType # What kind of action
context: Dict[str, any] # Situational information
constraints: Dict[str, any] # Boundaries and policies
success_criteria: Dict[str, any] # How to measure success
timestamp: str # ISO 8601 timestamp
parent_intent_id: Optional[str] # For intent chainsExample: Cost Monitor Detecting Anomaly
intent = Intent(
intent_id="intent_2024_001",
from_agent="cost_monitor",
to_agent="performance_optimizer",
intent_type=IntentType.INVESTIGATE,
context={
"anomaly_type": "cost_spike",
"service": "api_gateway",
"cost_increase_pct": 47,
"time_window": "last_4_hours",
"affected_resources": ["prod-api-gateway-01", "prod-api-gateway-02"]
},
constraints={
"response_time_sla": "15_minutes",
"max_diagnostic_cost": 10.0 # Don't spend more than $10 investigating
},
success_criteria={
"identify_root_cause": True,
"provide_remediation_options": True
},
timestamp="2024-01-15T14:23:01Z",
parent_intent_id=None
)Transport Layer
Intents can be transported via Message Queue (Kafka), gRPC, or Event Bus.
For this reference implementation, Kafka is used with agent-specific topics (e.g., agent.performance_optimizer.intents) to ensure durability and replayability—critical for debugging agent reasoning later.
2. Memory Architecture
The Three Memory Systems
Agents need three distinct types of memory:
- Working Memory: Short-term context for current reasoning loop (like RAM)
- Episodic Memory: Historical record of past interactions and outcomes
- Semantic Memory: Factual knowledge, learned patterns, domain expertise
Implementation: Vector Store + Structured DB
Semantic Memory uses a vector database for RAG (Retrieval-Augmented Generation):
from pinecone import Pinecone
from sentence_transformers import SentenceTransformer
class SemanticMemory:
def __init__(self, pinecone_api_key: str, index_name: str):
self.pc = Pinecone(api_key=pinecone_api_key)
self.index = self.pc.Index(index_name)
self.encoder = SentenceTransformer('all-MiniLM-L6-v2')
def store_knowledge(self, text: str, metadata: Dict):
"""Store a piece of knowledge with semantic embedding"""
embedding = self.encoder.encode(text).tolist()
self.index.upsert(vectors=[(
str(hash(text)),
embedding,
{"text": text, **metadata}
)])
def retrieve_relevant(self, query: str, top_k: int = 5):
"""Retrieve semantically similar knowledge"""
query_embedding = self.encoder.encode(query).tolist()
results = self.index.query(
vector=query_embedding,
top_k=top_k,
include_metadata=True
)
return [match['metadata'] for match in results['matches']]Episodic Memory uses a time-series database:
from dataclasses import dataclass
from datetime import datetime
import psycopg2
@dataclass
class Episode:
agent_id: str
intent_id: str
action_taken: str
outcome: str
success: bool
timestamp: datetime
context: Dict
class EpisodicMemory:
def __init__(self, db_connection_string: str):
self.conn = psycopg2.connect(db_connection_string)
def record_episode(self, episode: Episode):
"""Store an episode of agent behavior"""
with self.conn.cursor() as cur:
cur.execute("""
INSERT INTO episodes
(agent_id, intent_id, action_taken, outcome, success, timestamp, context)
VALUES (%s, %s, %s, %s, %s, %s, %s)
""", (
episode.agent_id,
episode.intent_id,
episode.action_taken,
episode.outcome,
episode.success,
episode.timestamp,
json.dumps(episode.context)
))
self.conn.commit()
def get_similar_past_situations(self, current_context: Dict, limit: int = 10):
"""Find past episodes with similar context"""
# In production, use embedding similarity here too
with self.conn.cursor() as cur:
cur.execute("""
SELECT * FROM episodes
WHERE context @> %s
ORDER BY timestamp DESC
LIMIT %s
""", (json.dumps(current_context), limit))
return cur.fetchall()Memory-Augmented Agent Reasoning
Here’s how the Cost Monitor agent uses memory when detecting an anomaly:
class CostMonitorAgent:
def __init__(self, semantic_memory: SemanticMemory, episodic_memory: EpisodicMemory):
self.semantic_memory = semantic_memory
self.episodic_memory = episodic_memory
def investigate_cost_spike(self, service: str, cost_increase_pct: float):
# Step 1: Retrieve relevant knowledge
knowledge = self.semantic_memory.retrieve_relevant(
f"cost spike in {service}"
)
# Step 2: Find similar past incidents
past_episodes = self.episodic_memory.get_similar_past_situations({
"service": service,
"anomaly_type": "cost_spike"
})
# Step 3: Synthesize with LLM
prompt = f"""
Current situation: {service} cost increased by {cost_increase_pct}%
Relevant knowledge from past:
{json.dumps(knowledge, indent=2)}
Similar past incidents:
{json.dumps(past_episodes, indent=2)}
Based on this context, what are the most likely causes and recommended actions?
"""
# Call LLM with augmented context
# ... reasoning logic here3. Policy Enforcement
Policy-as-Code with Open Policy Agent (OPA)
Agents need guardrails. A common pattern is using OPA to enforce policies declaratively.
Example Policy: Budget Constraints
package agent.policies
default allow_scaling = false
# Allow scaling if within budget and justified
allow_scaling {
input.action == "scale_up"
input.estimated_cost < data.budgets[input.service].remaining
input.justification.utilization > 0.8
}
# Always deny if service is marked for decommission
deny_scaling {
data.services[input.service].status == "decommissioning"
}
# Require approval for expensive operations
requires_human_approval {
input.estimated_cost > data.approval_thresholds.manager_approval
}Policy Enforcement in Agent Code
from opa_client import OPAClient
class CapacityPlannerAgent:
def __init__(self, opa_url: str):
self.policy_engine = OPAClient(opa_url)
def propose_scaling(self, service: str, scale_factor: float):
# Agent decides to scale based on metrics
estimated_cost = self.calculate_cost(service, scale_factor)
# Check policy before executing
policy_input = {
"action": "scale_up",
"service": service,
"estimated_cost": estimated_cost,
"justification": {
"utilization": 0.85,
"response_time_p99": 2.3 # seconds
}
}
result = self.policy_engine.evaluate("agent/policies/allow_scaling", policy_input)
if result.get("deny_scaling"):
self.log_policy_violation("scaling denied by policy")
return None
if result.get("requires_human_approval"):
self.request_human_approval(policy_input)
return None
if result.get("allow_scaling"):
return self.execute_scaling(service, scale_factor)
# Default deny
return None4. Failure Modes and Resilience
Critical Failure Scenarios
Failure Mode 1: Agent Reasoning Loop Hangs
Symptom: Agent gets stuck in an infinite planning loop, never commits to action.
Root Cause: Circular dependencies in reasoning (Agent A waits for B, B waits for A).
Mitigation:
class Agent:
MAX_REASONING_ITERATIONS = 10
REASONING_TIMEOUT_SECONDS = 30
def reason_and_act(self, intent: Intent):
iterations = 0
start_time = time.time()
while not self.has_decision():
if iterations >= self.MAX_REASONING_ITERATIONS:
self.log_error("Reasoning loop exceeded max iterations")
self.fallback_to_human()
return
if time.time() - start_time > self.REASONING_TIMEOUT_SECONDS:
self.log_error("Reasoning timeout")
self.fallback_to_human()
return
self.reasoning_step()
iterations += 1Failure Mode 2: Memory Consistency Issues
Symptom: Agent makes decisions based on stale data because another agent updated shared memory.
Root Cause: No transactional guarantees on shared memory reads/writes.
Mitigation: Use optimistic locking with version stamps:
class SharedMemory:
def __init__(self, redis_client):
self.redis = redis_client
def read_with_version(self, key: str):
"""Read data with version stamp for optimistic locking"""
data = self.redis.hgetall(key)
return {
"value": json.loads(data[b'value']),
"version": int(data[b'version'])
}
def write_if_version_matches(self, key: str, value: any, expected_version: int):
"""Write only if version hasn't changed (optimistic lock)"""
lua_script = """
local current_version = redis.call('HGET', KEYS[1], 'version')
if current_version == ARGV[2] then
redis.call('HSET', KEYS[1], 'value', ARGV[1])
redis.call('HINCRBY', KEYS[1], 'version', 1)
return 1
else
return 0
end
"""
result = self.redis.eval(lua_script, 1, key, json.dumps(value), str(expected_version))
return result == 1Failure Mode 3: Policy Conflicts
Symptom: Two policies contradict each other (e.g., “always scale for performance” vs “never exceed budget”).
Root Cause: Policies written independently without conflict resolution.
Mitigation: Policy priority system:
package agent.policies
# Priority levels: safety > compliance > cost > performance
default priority = 0
# Safety policies have highest priority
priority = 100 {
input.affects_user_data
}
# Compliance is second
priority = 90 {
input.regulation == "gdpr"
}
# Cost constraints
priority = 50 {
input.estimated_cost > data.budgets.monthly_limit
}
# Performance optimization is lowest
priority = 10 {
input.optimization_type == "performance"
}Failure Mode 4: Intent Flooding
Symptom: One agent sends thousands of intents, overwhelming downstream agents.
Root Cause: No rate limiting on inter-agent communication.
Mitigation: Implement a Token Bucket Rate Limiter at the mesh ingress. Do not assume agents will self-regulate; they can and will loop infinitely if unchecked.
5. Observability: Tracing Agent Decisions
The Challenge
Traditional observability tracks requests, latency, errors. For agents, we need to track reasoning chains:
- What information did the agent consider?
- What alternatives did it evaluate?
- Why did it choose this action over others?
- What was the expected outcome vs actual outcome?
Reasoning Trace Structure
@dataclass
class ReasoningTrace:
trace_id: str
agent_id: str
intent_id: str
timestamp: datetime
# Reasoning steps
context_retrieved: List[Dict] # What memory was accessed
alternatives_considered: List[Dict] # What options were evaluated
decision_rationale: str # Why this choice
selected_action: Dict # What action was taken
confidence_score: float # How confident (0-1)
# Outcome tracking
expected_outcome: Dict
actual_outcome: Optional[Dict] # Filled in later
success: Optional[bool] # Filled in later
# The collector sends these traces to Tempo/Jaeger for visualization
# allowing you to query: "Show me all reasoning chains that resulted in scaling > 5x"Example: Cost Monitor’s Reasoning Trace
trace = ReasoningTrace(
trace_id="trace_2024_001",
agent_id="cost_monitor",
intent_id="intent_2024_001",
timestamp=datetime.now(),
context_retrieved=[
{"source": "semantic_memory", "doc": "Past cost spike in api_gateway caused by DDoS"},
{"source": "episodic_memory", "episode": "2023-11-15: Similar spike resolved by rate limiting"}
],
alternatives_considered=[
{"action": "scale_down", "estimated_savings": 1200, "risk": "may impact performance"},
{"action": "enable_rate_limiting", "estimated_savings": 0, "risk": "may block legitimate traffic"},
{"action": "investigate_further", "estimated_cost": 50, "risk": "delays resolution"}
],
decision_rationale="Historical data shows rate limiting resolved similar spikes without scaling. Low risk, immediate action.",
selected_action={"action": "enable_rate_limiting", "threshold": "1000_req_per_min"},
confidence_score=0.78,
expected_outcome={"cost_reduction_pct": 40, "resolution_time_minutes": 5}
)6. Production Architecture: The Complete System
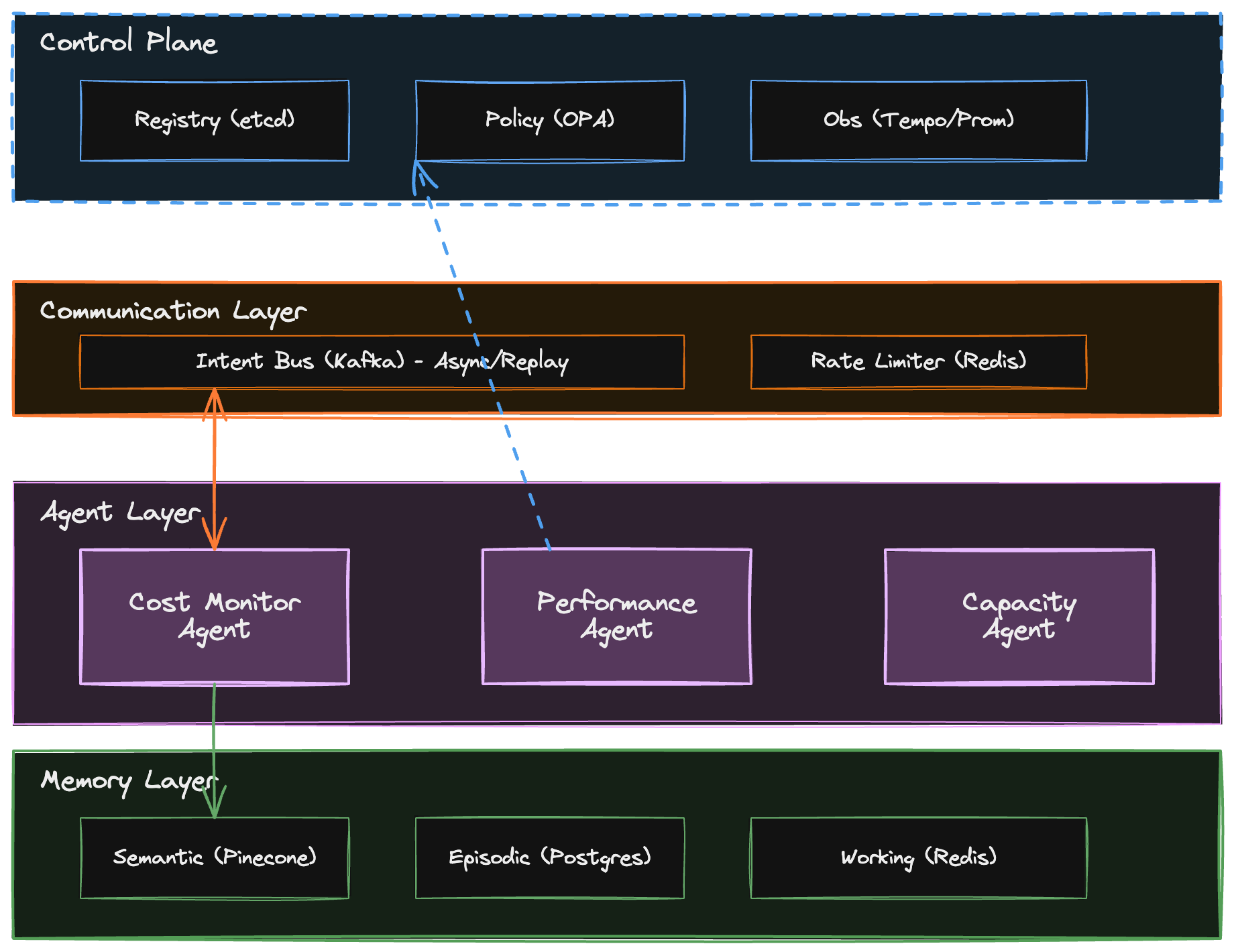
Deployment Topology
As illustrated in the diagram above, the deployment consists of four distinct layers:
-
Agent Control Plane: Manages governance and visibility.
- Agent Registry (etcd): Service discovery for agents.
- Policy Server (OPA): Centralized guardrails.
- Observability (Tempo + Prometheus): Tracing reasoning chains.
-
Communication Layer: Handles async message passing.
- Intent Bus (Kafka): Durable event log.
- Rate Limiting (Redis): Prevents flooding.
-
Agent Layer: The autonomous workers (Cost, Performance, Capacity).
-
Memory Layer: Persistent state.
- Semantic (Pinecone): Long-term knowledge.
- Episodic (Postgres): Audit logs and history.
- Working (Redis): Short-term context.
7. When NOT to Use Agent Mesh
Agent Mesh adds complexity. Don’t use it when:
- The workflow is deterministic: If you can write it as a DAG, do that instead
- Low tolerance for unpredictability: Financial transactions, safety-critical systems
- Latency requirements under 100ms: Agent reasoning adds overhead
- Team lacks ML ops expertise: Debugging agentic systems requires new skills
- Data volume is low: The benefits of adaptive decision-making don’t justify the complexity
Rule of thumb: Use Agent Mesh when the value of adaptive, context-aware decision-making exceeds the cost of added complexity and unpredictability.
Conclusion
Building production-ready agentic systems requires rethinking multiple layers:
- Communication: Intent-based protocols instead of rigid APIs
- Memory: Semantic and episodic memory as architectural primitives
- Policy: Declarative governance with priority-based conflict resolution
- Resilience: New failure modes (reasoning loops, memory conflicts, intent flooding)
- Observability: Tracing reasoning chains, not just requests
The Agent Mesh pattern provides a structured framework for these concerns. But it’s not a silver bullet — it introduces trade-offs around predictability, latency, and operational complexity.
Start small. Build one agent. Give it memory. Add policies. Observe how it behaves. Learn where it fails. Only then add more agents to the mesh.
The age of agentic AI is here. The architectures that succeed will balance autonomy with control, adaptability with predictability, and innovation with pragmatism.
Back to Part 1: Architecting the Age of Agentic AI